
Hace unas semanas revisé el caso de un ecommerce que llevaba tres meses optimizando su tienda online porque Page Speed le marcaba un 54. Habían minificado CSS, comprimido imágenes, activado lazy loading en todas las fichas. La puntuación subió a 82. El problema es que la tasa de abandono en móvil seguía clavada en el mismo porcentaje. La tienda seguía perdiendo ventas en el mismo punto del embudo. El numerito verde no había cambiado nada que importara realmente al negocio.
¿Cuántas veces has visto o pagado un informe de rendimiento que se reduce a una captura de Lighthouse y una lista de sugerencias automáticas? En mi experiencia auditando más de 120 proyectos en los últimos cuatro años, eso es exactamente lo que entrega alrededor del 80% de los informes que llegan a mis manos para segunda opinión. Una captura, una lista, terminología que suena impresionante y cero contexto de negocio.
Lo que voy a desgranar aquí es cómo hacer una auditoría de contenido seo para mejorar la velocidad web que identifique causas raíz reales, no síntomas decorativos, cómo priorizar intervenciones por impacto medible y por qué la diferencia entre un diagnóstico WPO profesional y un informe automático puede traducirse en meses de trabajo tirado a la basura.
Indice
- 1 ¿Qué síntomas delatan un problema de velocidad web real?
- 2 ¿Por qué tu nota en Page Speed Insights no sirve como auditoría?
- 3 Anatomía de una auditoría de velocidad web que diagnostica causas
- 4 ¿Cómo priorizar mejoras tras la auditoría?
- 5 Qué diferencia una auditoría WPO profesional de un informe automático
¿Qué síntomas delatan un problema de velocidad web real?
La primera trampa está en confundir el síntoma con la enfermedad. Una web lenta no siempre lo parece si la pruebas desde tu portátil con fibra óptica en la oficina. Y una que parece rápida en datos de laboratorio puede arrastrar problemas severos que solo emergen cuando el tráfico real, en dispositivos reales, golpea el servidor a las 10 de la mañana.
¿Sabes en cuántos proyectos he visto a un equipo de desarrollo declarar «todo optimizado» porque su test local cargaba en 1.2 segundos? Al menos en 20 de los últimos 35 que hemos auditado durante los dos últimos años. La prueba local, con caché caliente y fibra simétrica, es la mentira más cómoda del rendimiento web.
Métricas evidentes que todos miran primero
Largest Contentful Paint, Cumulative Layout Shift, Interaction to Next Paint. Las Core Web Vitals son lo primero que cualquier herramienta te escupe, y como punto de partida tienen valor. Reducir un diagnóstico de rendimiento completo a tres números es otra cosa: equivale a evaluar la salud de un edificio mirando exclusivamente la fachada.
Si el LCP supera los 2.5 segundos, se enciende la primera alarma. Un CLS por encima de 0.1 señala inestabilidad visual. Un INP que rebase los 200 milisegundos apunta a problemas de interactividad severos. Hasta aquí, cualquier persona con acceso a Search Console o Page Speed puede llegar sin despeinarse. La cuestión real es: ¿y después qué haces con eso?
Cuando en nuestros análisis encontramos un LCP malo, la pregunta inmediata no es cómo lo bajo sino qué elemento específico lo provoca, en qué plantilla y bajo qué condiciones de red. Un hero image sin comprimir en la home es radicalmente diferente a un bloque de JavaScript que retrasa la pintura del contenido principal solo en páginas de categoría con más de 40 productos. Misma métrica roja, dos causas que no comparten ni diagnóstico ni solución.
Señales invisibles que solo aparecen con datos de usuarios reales
Analizar logs de servidor durante años me enseñó algo fundamental: los datos de laboratorio mienten por omisión. Lighthouse ejecuta su test desde un entorno controlado con throttling simulado. Tus usuarios reales navegan desde un Android de 2019 con 3G inestable en el metro de Madrid. Son dos realidades que apenas se reconocen entre sí.
Chrome UX Report, la monitorización RUM si la tienes implementada, cuentan una historia completamente distinta. He documentado casos donde el percentil 75 de LCP en laboratorio marcaba 1.8 segundos y en campo se disparaba a 4.2. ¿La causa? Scripts de terceros que Lighthouse nunca ejecutaba porque el test se hacía sin aceptar cookies, así que los tags de analytics, re-marketing y chat jamás cargaban durante la medición sintética.
¿Cuántos de esos informes automáticos que te han entregado incluían datos de campo segmentados por tipo de dispositivo, ubicación geográfica y tipo de conexión? En lo que llevo visto, menos del 15%. Y es precisamente en esa segmentación donde se esconden los diagnósticos con valor real para el negocio.
Total, que si tu evaluación de rendimiento solo recoge lo que Lighthouse observa en condiciones de laboratorio, estás diagnosticando a un paciente sedado. Necesitas al paciente despierto, moviéndose y en su entorno cotidiano para sacar conclusiones que sirvan de algo.

¿Por qué tu nota en Page Speed Insights no sirve como auditoría?
Vamos a decirlo sin rodeos: Page Speed Insights es una herramienta de screening, no de diagnóstico. Confundir ambas cosas funciona igual que tratar una neumonía guiándote solo por la lectura del termómetro. El termómetro te confirma que algo falla. No te dice qué, ni dónde, ni por qué.
¿Significa que Page Speed no vale para nada? Claro que no. Su función es alertar, no resolver. Cuando alguien te entrega un «informe de velocidad» que básicamente es una captura de esa herramienta con comentarios al margen, lo que estás pagando es que alguien te pase el termómetro. La interpretación clínica es otro servicio completamente distinto.
Lo que mide un test sintético frente a lo que experimenta el usuario
Un test sintético (Lighthouse, WebPageTest en modo estándar, GTmetrix) ejecuta la carga de una URL desde un servidor específico, con un perfil de CPU y red predefinidos. Siempre la misma URL de partida, siempre el mismo punto de origen geográfico, siempre sin estado de sesión previo ni cookies aceptadas.
Ahora pon al usuario real en la ecuación. Carga tu web desde Segovia a las 8 de la mañana con un Xiaomi Redmi Note 9 y cobertura 4G irregular. Viene de un resultado orgánico, no tiene caché previo. Le salta el banner de cookies, acepta, y entonces solo entonces se ejecutan los 14 scripts de terceros que tu medición sintética jamás llegó a procesar.
Cuando cruzamos estos datos con las métricas reales de CrUX en proyectos que gestionamos desde SEO Valladolid, encontramos brechas de hasta un 120% entre el tiempo de carga en laboratorio y el que registra el percentil 75 de usuarios reales. Esa diferencia no es un matiz técnico: es la distancia entre creer que tu web funciona bien y que tus usuarios estén abandonando antes de ver el primer contenido.
Cuando una web con 90 puntos carga peor que otra con 60
Suena contradictorio, pero lo he documentado más veces de las que me gustaría admitir. Un blog corporativo con contenido estático, pocas imágenes y cero JavaScript externo puede sacar 95 en Lighthouse sin esfuerzo. Pon al lado una landing de producto con vídeo embebido, comparador dinámico y chat en vivo: 58 puntos. ¿Cuál convierte más? La de 58, por goleada, porque su arquitectura de carga prioriza el contenido above-the-fold y el usuario encuentra lo que busca antes de tener tiempo de frustrarse.
Lighthouse pondera métricas con pesos fijos que no distinguen entre un blog y un checkout. No sabe que el CLS de tu carrusel resulta irrelevante si el usuario nunca llega a verlo sin hacer scroll. Esa falta de contexto convierte la cifra en ruido cuando la usas como criterio único de decisión. Y sin embargo, sigue siendo lo primero que piden los clientes y lo primero que entregan la mayoría de informes. Curioso, ¿no?
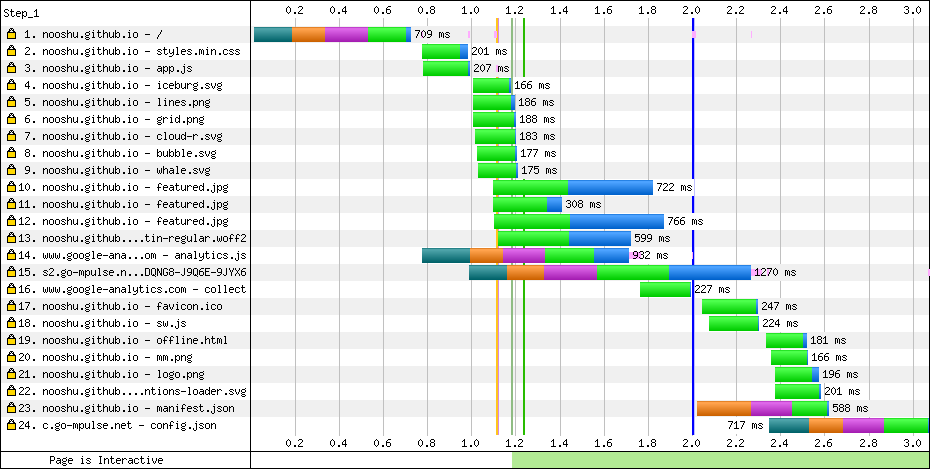
Anatomía de una auditoría de velocidad web que diagnostica causas
Aquí es donde se separa el grano de la paja. Un diagnóstico WPO real descompone el rendimiento en capas: servidor, red, recursos, renderizado y experiencia percibida. Cada capa requiere herramientas distintas, datos distintos y, lo que la mayoría olvida, criterio experto para interpretar lo que esos datos significan en el contexto específico de cada proyecto.
¿Qué incluye una radiografía de rendimiento que supere el nivel de termómetro? Tres pilares que voy a desmontar pieza a pieza.
Tiempo de respuesta del servidor y latencia real
El TTFB (Time to First Byte) es donde empieza absolutamente todo. Si tu servidor tarda 800 milisegundos en responder, da igual lo optimizado que esté el fronted: has quemado casi un segundo antes de que el navegador reciba un solo byte de contenido. Y sin embargo, es la métrica que menos protagonismo recibe en los informes automáticos porque Lighthouse la menciona de pasada, casi como nota al margen.
Cuando diagnostico el tiempo de respuesta, mido desde múltiples ubicaciones geográficas y en franjas horarias distintas. He encontrado servidores que responden en 180ms a las 3 de la madrugada y se disparan a 1.4 segundos a las 10 de la mañana por sobrecarga de procesos PHP en hosting compartido. Mides una sola vez y obtienes un número. Mides 50 veces distribuidas en el día y obtienes un patrón que realmente cuenta una historia.
La cosa es que un TTFB alto no siempre significa «servidor lento» a secas. Puede ser un plugin que ejecuta consultas a base de datos sin cachear resultados. Puede ser un CDN mal configurado que añade un salto extra en lugar de acortar la ruta. Puede ser que HTTP/2 no esté activo y las conexiones se serialicen absurdamente. Cada causa exige una solución distinta, y ningún informe automatizado desglosa esto con el nivel de detalle necesario.
En un caso de finales de 2023, encontramos que un WooCommerce tardaba 2.1 segundos de TTFB exclusivamente en fichas con más de 3 variaciones de producto. El origen era un hook de un plugin de inventario que consultaba stock en tiempo real por cada variación al cargar la página. La solución, cachear esa consulta con transients de WordPress, redujo el TTFB a 290ms. Spoiler: ninguna herramienta automática habría señalado ese plugin como causa raíz. Tuvimos que revisar query logs, desactivar plugins uno a uno y medir de forma aislada. Trabajo manual, sí. Resultado preciso, también.
Cascada de recursos y bloqueos de renderizado
Imagina que cada recurso que tu web necesita cargar (CSS, JavaScript, fuentes, imágenes) es un paso en una cadena de montaje. Si un paso bloquea el siguiente, toda la línea se paraliza. Exactamente eso ocurre cuando un archivo CSS render-blocking de 340KB tiene que descargarse y parsearse íntegro antes de que el navegador pinte un solo píxel en pantalla.
En WebPageTest, la cascada de carga concentra más información en un solo gráfico que la mayoría de informes completos. Cada barra horizontal representa un recurso, y su longitud y posición te muestran cuánto tarda en descargarse y cuánto retrasa a los demás. ¿Ves un JavaScript de terceros que tarda 1.2 segundos y arrastra una línea de bloqueo que se extiende hasta el final del render? Ahí tienes tu cuello de botella principal, probablemente responsable de más degradación que todas las imágenes sin comprimir juntas.
Mi rutina estándar incluye comparar la cascada con JavaScript habilitado y deshabilitado. La brecha entre ambas revela cuánto impacto real tienen tus scripts en el tiempo de renderizado del contenido principal. En la mayoría de webs que paso por este proceso, desactivar JS de terceros reduce el tiempo de pintura del LCP entre un 35% y un 60%. Debería dar vergüenza. (Y me incluyo: en 2021 monté un proyecto propio donde el widget de chat de soporte añadía 1.8 segundos al render inicial. Tardé semanas en identificarlo porque solo miraba la puntuación global como un autómata. Lección aprendida a base de perder posiciones.)
Diagnóstico por tipo de plantilla y dispositivo
¿Tu home carga en 1.5 segundos? Estupendo. ¿Y la categoría con 120 productos paginados? ¿Y la ficha con 8 imágenes y un vídeo embebido? ¿Y el checkout con pasarela de pago integrada? Cada tipo de plantilla tiene un perfil de rendimiento propio, y evaluarlos como si fueran intercambiables invalida cualquier conclusión seria.
Un chequeo de velocidad profesional selecciona URLs representativas de cada tipo de página (home, categoría, producto, artículo, landing, checkout) y mide cada una por separado, diferenciando móvil de escritorio. Después cruza los datos sintéticos con los de campo disponibles en CrUX, segmentados por grupo de páginas. Solo así detectas que tu problema real no está en la home (que todos miden) sino en las fichas de producto (que casi nadie audita individualmente).
¿Cómo priorizar mejoras tras la auditoría?
Ya tienes el diagnóstico completo encima de la mesa. Ahora llega la pregunta que separa a los profesionales de los aficionados: ¿por dónde empezar? Cuando tu análisis revela 23 problemas de rendimiento y los atacas todos simultáneamente, o peor, empiezas por el que parece más sencillo, vas a desperdiciar tiempo y presupuesto de forma espectacular.
Respuesta corta: impacto dividido entre esfuerzo. La respuesta larga necesita contexto, así que vamos con ella.
Matriz de impacto frente a esfuerzo técnico
Nosotros usamos una matriz 2×2 que parece obvia pero resulta sorprendentemente poco frecuente en el sector. Eje horizontal: esfuerzo técnico medido en horas de desarrollo más riesgo de regresión. Eje vertical: impacto estimado en Core Web Vitals y en métricas de negocio como tasa de rebote, conversión y tiempo en página. El cuadrante superior izquierdo, alto impacto con bajo esfuerzo, se ejecuta primero. Sin negociación ni excepciones.
¿Ejemplos tangibles? Activar compresión Brotli en servidor Apache: 30 minutos de implementación, reducción del peso de transferencia entre un 15% y un 25%. Eso entra directo en el cuadrante prioritario. Reescribir el frontend completo en un framework headless para eliminar render-blocking: tres meses de desarrollo, mejora teórica del 40% en LCP, pero con riesgo elevado de regresión SEO si la migración no se planifica con cuidado milimétrico. Eso va al cuadrante de planificación estratégica a medio plazo.

Revisando el impacto de las últimas 10 evaluaciones de rendimiento que hemos ejecutado, las tres intervenciones con mayor retorno consistente son: optimizar la carga de third-party scripts (defer, async o carga condicional tras interacción), implementar caché de objetos en servidor (Redis o Memcached) y servir imágenes en formato WebP o AVIF con dimensiones correctas según el viewport. Ninguna requiere más de un día de trabajo. Las tres combinadas suelen mejorar el LCP de campo entre un 30% y un 45%.
Errores de priorización que retrasan resultados meses
Vamos, que el error más caro que sigo viendo es optimizar lo visible antes que lo estructural. Comprimir imágenes cuando tu servidor tarda 1.5 segundos en responder es como repintar la fachada de un edificio con los cimientos agrietados. Queda bonito en el informe («hemos reducido 2MB el peso de las imágenes»), pero el usuario sigue esperando 4 segundos a que algo aparezca en pantalla.
Segundo error clásico: perseguir la puntuación de Lighthouse en lugar de las métricas de campo reales. He visto equipos dedicar 80 horas a eliminar un CLS residual de 0.02 (que ya estaba en zona verde) mientras ignoraban un INP de 380ms que destrozaba la experiencia táctil en móvil. ¿La razón? El CLS aparecía primero en la lista de oportunidades. Priorizar por el orden en que la herramienta presenta los datos, en vez de por su impacto real en usuarios… duele solo de pensarlo. Y lo peor es que tres meses después seguían sin entender por qué la tasa de conversión móvil no mejoraba.
Qué diferencia una auditoría WPO profesional de un informe automático
A estas alturas probablemente ya intuyes la respuesta. Pero conviene ser explícito porque esta distinción le ahorra a mucha gente miles de euros invertidos en informes decorativos que nadie llega a implementar.
Un informe automático te dice qué está mal según un algoritmo predefinido. Un diagnóstico profesional te explica por qué está mal, qué consecuencia tiene para tu negocio específico y en qué orden deberías intervenir para maximizar el retorno de cada hora de desarrollo invertida.
Elementos que debe incluir un diagnóstico de velocidad real
Tras haber ejecutado más de 120 análisis de rendimiento en los últimos cuatro años, tengo bastante claro qué separa a uno que genera resultados de uno que acaba almacenando polvo digital en alguna carpeta de Drive. Un diagnóstico WPO completo incluye, como mínimo: medición combinando datos de laboratorio y de campo, segmentación por tipo de plantilla, análisis de cascada con identificación de cuellos de botella específicos, evaluación de TTFB bajo carga variable, inventario de scripts de terceros con impacto individual cuantificado, y una hoja de ruta priorizada con estimación de mejora y esfuerzo por cada acción.
¿Suena a mucho trabajo? Lo es. Una evaluación de rendimiento seria lleva entre 15 y 25 horas según la complejidad del proyecto. Cuando te ofrecen una por 200 euros y en 48 horas, ya sabes lo que vas a recibir: Lighthouse con maquillaje corporativo. (No digo que no haya existido algún profesional capaz de hacer buen trabajo en menos tiempo. Digo que no he conocido a ninguno personalmente, y llevo una década en esto.)
Mira, al final la diferencia tangible es sencilla: tras un diagnóstico real, tu equipo técnico tiene un documento que puede ejecutar punto por punto, con resultados predecibles y medibles. Tras un informe automático, tienes una lista de deseos genérica que necesita otro profesional para interpretarla antes de que nadie pueda tocar una sola línea de código.
Señales de que tu auditoría se quedó en la superficie
¿El último informe de rendimiento que recibiste cumple tres o más de estos patrones? Probablemente necesitas una segunda opinión con mayor profundidad:
- Solo utiliza datos de una herramienta, generalmente Lighthouse o GTmetrix, sin cruzar con datos de campo.
- No diferencia entre tipos de página: mide la home y extrapola al resto como si toda la web se comportara igual.
- Las recomendaciones son genéricas, del tipo «comprimir imágenes», «minificar CSS» o «usar CDN», sin especificar qué recursos concretos, en qué plantillas y con qué prioridad.
- No menciona CrUX ni monitorización RUM, ni explica la brecha entre datos sintéticos y experiencia real.
- Ausencia total de análisis de scripts de terceros y su impacto individual en el renderizado.
- No presenta una priorización basada en criterios de impacto frente a esfuerzo técnico.
¿Reconoces ese patrón? No estás solo. La mayoría de las evaluaciones de rendimiento que circulan por el sector son variaciones del mismo template automático con logotipo diferente arriba y factura distinta debajo. La excepción existe y merece la pena buscarla, pero hay que hacerlo con criterio y sabiendo qué preguntas formular antes de contratar.
